由于“打怪”失败,最近一直在牛客网上刷题复习备战春招。其中有个 Java专题复习题库,我刷着刷着就想把它爬下来!那么就开始吧。
页面是这个样子的,
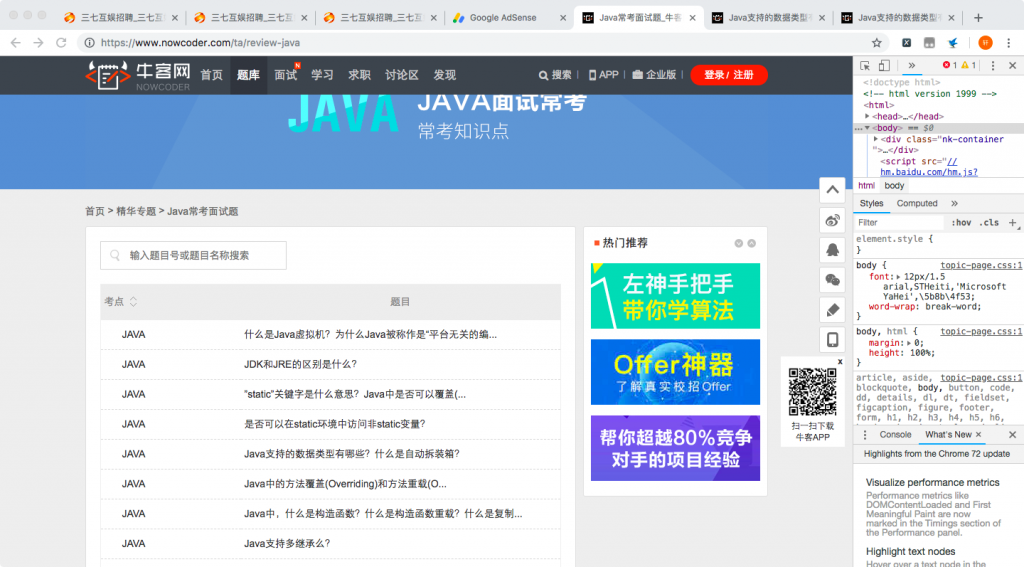
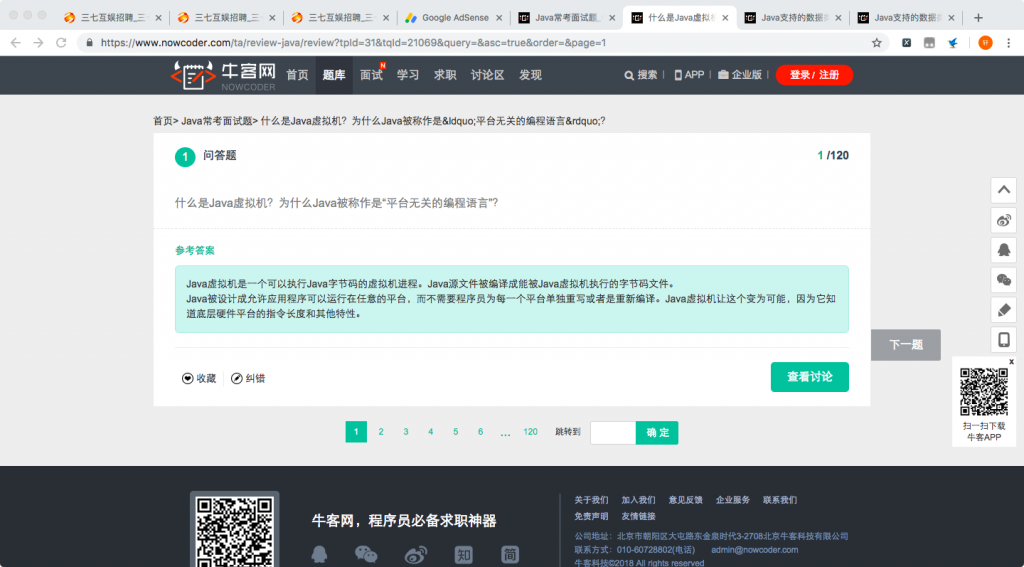
分析网页链接,发现没有加密,例如第一题的详情页为:https://www.nowcoder.com/ta/review-java/review?query=&asc=true&order=&page=1 可以先自行构造链接,代码如下:
urls = ['https://www.nowcoder.com/ta/review-java/review?query=&asc=true&order=&page={}'.format(str(i)) for i in range(1,121)]
在选中要抓取的数据部分,右击【检查】,发现答案都在 class=”design-answer-box” 标签内。使用谷歌浏览器插件 XPath helper 进行 Copy XPath ,“/html/body/div[1]/div[2]/div[2]/div[2]/div[1] ”。
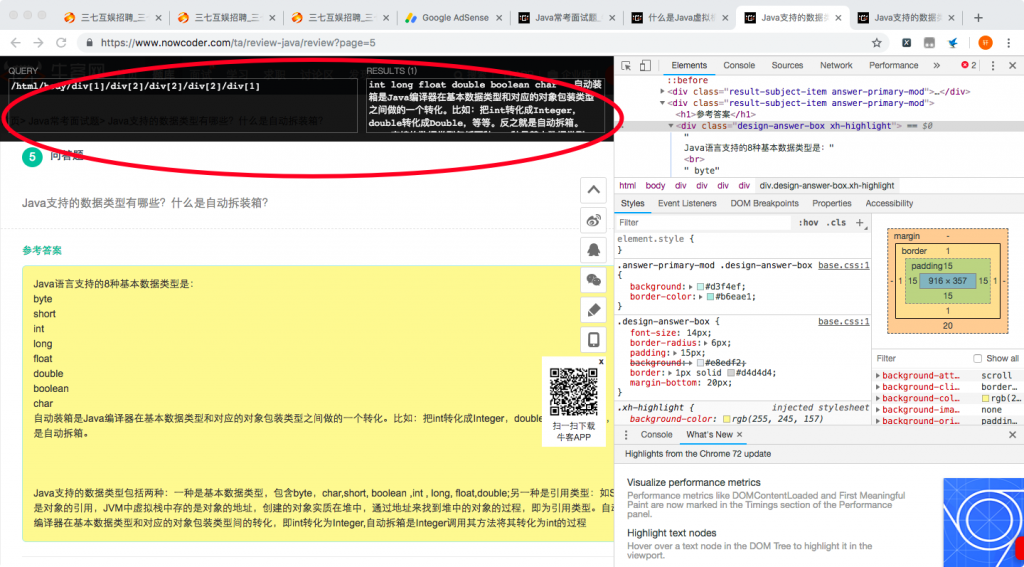
主要思路:
- 构造网页链接
- 编写爬虫函数(保存数据到文件)
- for 循环进行调用函数
代码如下:
import requests
import time
from lxml import etree
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#/html/body/div[1]/div[2]/div[2]/div[2]/div[1]
f = open('./JavaPros.md','a+')
def get_info(url,n):
res = requests.get(url, headers=header)
selector = etree.HTML(res.text)
question = '##### '+str(n)+'、'+selector.xpath('/html/body/div[1]/div[2]/div[2]/div[1]/div[2]/text()')[0].lstrip('\n')+'\n'
answer = selector.xpath('/html/body/div[1]/div[2]/div[2]/div[2]/div[1]//text()')
answer = "".join(answer)
answer = '```\n'+answer.lstrip('\n')+'\n```\n'
f.write(question+answer)
if __name__ == '__main__':
urls = ['https://www.nowcoder.com/ta/review-java/review?query=&asc=true&order=&page={}'.format(str(i)) for i in range(1,121)]
i = 1;
for url in urls:
print(url)
get_info(url,i)
i = i + 1
time.sleep(1)
f.close()结果:
